

Published July 24, 2017
Ditch Databases: Achieving Higher Availability Without Traditional Storage
For critical platforms within customer-centered organizations, high availability is a top priority. High availability, however, is a constantly moving target. The more a platform is used, the more it needs to be available, providing consistent performance and correct task execution.
I am going to discuss a design strategy unique to platforms that require both high scalability and high availability. That design strategy involves reducing and removing the need for databases.
Why eliminate the database
Databases are a necessary evil when it comes to IT architecture. On one hand, they provide consistent storage and retrieval of data both big and small. On the other hand, they become a common failure point or, as we will explore further, a complexity.
One of the rules of thumb for designing high-availability platforms is to constantly minimize complexity. Complexity comes in many forms, from operational to implementation. Complexity can rear its ugly head and often create more problems than it’s worth.
While there are many types of databases, each with their unique characteristics, one thing they all have in common is that they increase the complexity of the platform as a whole. To explain this further, let’s break down a few ways in which databases increase complexity.
Operational knowledge
While database knowledge is a common skill in today’s technical world, the truth of the matter is that database administration and usage is a discipline. When a platform that utilizes a database requires high availability, that platform must also have engineers who can manage and effectively make use of that database.
In most platforms, this is not a problem. Having a handful of database experts around is sufficient, as they can often be shared amongst multiple platforms. However, this becomes more of a challenge at scale.
When the platform in question must be available at all times, using shared engineers is often problematic. When engineers are focused on multiple platforms, they often lose focus on any single platform and take longer to resolve issues. Or worse, as they scale out, they are unable to focus on the proactive measures to identify issues before they become outages.
Often, when a platform requires extremely high availability or continuous availability, engineers are dedicated to these platforms. In these cases, it is always critical to maintain a base set of skills within the engineering team. The more skills required, the more complicated it is to maintain a safe level of operational knowledge.
Performance
Another complexity introduced by databases is the performance of the database itself. When a platform is first created, a lot of attention is paid to getting performance just right. Sometimes this means tuning the database and sometimes it just works out of the box (depending on the database in use).
After time has passed, unless there is constant focus on measuring and adjusting the performance of the database, performance eventually starts to get worse and worse. Maybe someone notices these changes in performance: if not, performance issues tend to show themselves in the form of production problems.
For example, maybe an application starts to take longer for certain requests or, worse, the requests start to time out and end users are no longer able to use the service.
These scenarios occur all the time. It’s possible to proactively identify and mitigate these types of issues, but then we go back to maintain a base level of operational knowledge and skill.
Upgrades can be painful
In general, upgrading a production database can be quite painful. While some databases have significantly reduced the pain of upgrades, for most databases this involves a very intricate process. Whether it’s the need to export and import the database or the downtime required to perform the upgrade, these types of activities tend to be very tedious, often not conducive to being automated, and in general, prone to errors.
Again, these are things that skilled engineers can mitigate; however, doing so also distracts those skilled engineers from other tasks that may be more meaningful.
Data replication and resiliency
Data resiliency is the most complicated aspect of running a highly available platform. This is true whether we are talking about databases or any other data storage system.
While there are several newer open source databases that have integrated data replication into the base product, in general data replication has always added significant maintenance and monitoring overhead.
One complicated aspect of data replication is the timing around automated failover (a necessity for many high-availability platforms) and data synchronization. If you are using an asynchronous data replication strategy with an automated application failover, it is entirely possible to have application traffic on the secondary system before the data is available.
Synchronous data replication on the other hand brings its own set of challenges in day-to-day performance. Backups are another pain point. When you introduce backups, you now need to test those backups. They need to be maintained in the same way as any other component of the platform.
Reducing complexity, by reducing database usage
While these examples of database complexities can be compensated for, it is key to remember that doing so increases the complexity of the platform. The more complex a platform, the more difficult it is to maintain availability.
The caveat to the above statement is that in many cases high availability in itself brings complexity. Sometimes we must introduce additional complexity to provide high availability to the platform. The key to keeping complexity down is to make trade-offs whenever possible.
This is the crux of the no database philosophy. If it is possible to reduce the complexity of an application by reducing the need for a database, doing so will benefit the platform.
To help drive this point home, let’s look at a common use case where reliance on databases can be reduced or eliminated.
A typical high-availability implementation
The use case we will explore is a basic REST API that provides currency conversion functionality. This type of REST API is extremely common amongst financial applications.
A typical implementation of a REST API such as this would be a simple application with a database backend. Without taking into consideration a high-availability need for this application, a single application instance and a single database instance would be more than sufficient (Figure 1).
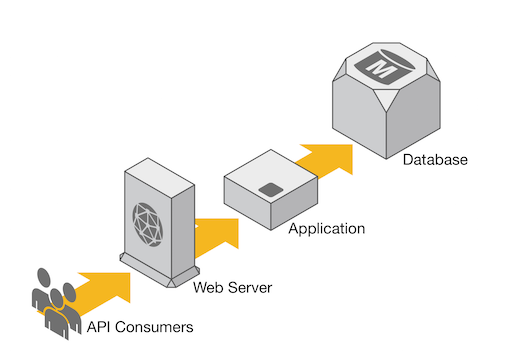 Figure 1
Figure 1
However, when deploying this type of application into a highly available environment, the design changes quite a bit, especially as the need arises to ensure the application is available across multiple data centers.
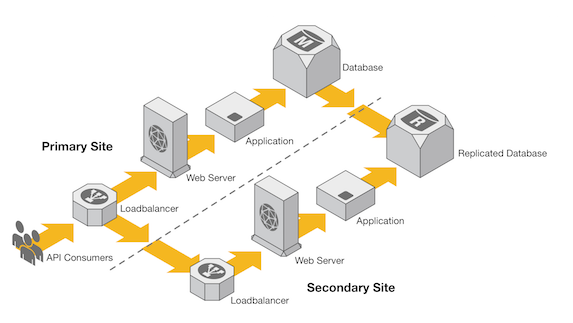 Figure 2
Figure 2
Figure 2 depicts a typical active-passive multi-site deployment, where we have a primary database in the primary site that receives updates and a replicated database in the secondary site. This type of deployment is fairly standard for high availability. It is simple in the context of high-availability deployments; however, by adding this data replication, we just added an extra layer to our design.
What happens if this replication fails and a failover to the secondary site is required? Would this service then start returning invalid results?
Moving the DB down the stack
Data replication is one of the most complex tasks associated with managing a database. One strategy to mitigate this is to move the complexity of data replication and management further down the stack, adding layers to compensate for failure.
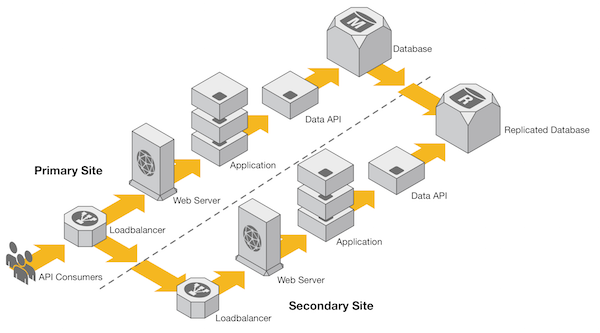 Figure 3
Figure 3
Figure 3 depicts a different approach to the earlier multi-site deployment. In this implementation, there are two main application components: the Application and a Data API.
In this design, rather than going directly to the database, the Application periodically calls the Data API service to get the latest and greatest currency-conversion data. Since this type of data is generally small in volume, the application can simply store the returned data in-memory for a predetermined time frame.
With this approach, the intricacies of interacting with and managing a database are pushed to the Data API layer, leaving the application free to focus on performing the currency conversion. If the Data API layer or Database were to go down, using this strategy the end user would not experience any impact. Since the application uses the currency-conversion data in memory, it is possible to keep the primary function of the application available while the database and Data API layer are unavailable.
With this strategy, we don’t necessarily eliminate the need for a database. Rather, we push it to a single system that makes the platform easier and less risky to manage.
Eliminate replication
Another method for reducing the complexities introduced by data replication is to move the data replication methodology away from the database itself (Figure 4).
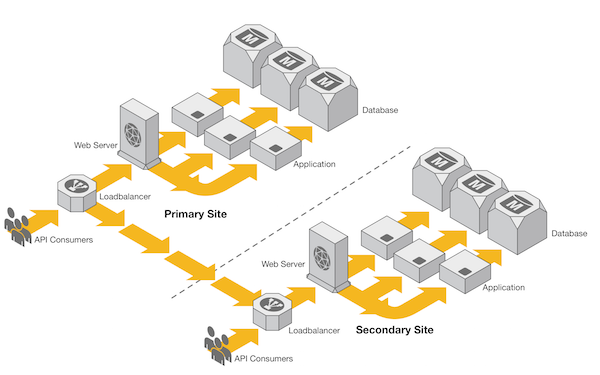 Figure 4
Figure 4
Many times, currency-conversion data is provided from external sources. Whether it is a file feed or even a series of external API calls, the reality is that the currency-conversion data is rarely ever locally generated. With this in mind, Figure 4 depicts a scaled-out version of our multi-site deployment. However, there is one difference; there is no database replication.
A simple strategy for applications such as this is to simply decouple each application instance from each other. This is also known as a shared nothing architecture.
This concept works with our currency-conversion API by relying on each application instance to query or receive up-to-date currency-conversion data and store the data within an isolated database instance. Since each instance is doing this independently, there is no need to replicate data at a database layer. This type of architecture is also beneficial to applications that perform mostly read operations; the read operations will gain a performance advantage from having the database localized for each application instance.
The only caveat to this strategy is that sometimes an application instance can start returning different information than the rest of the nodes within the cluster. This can be mitigated by placing checks and balances into the application architecture, but this can create its own set of problems.
With this strategy, it is possible to remove the complexity of managing database replication; however, we are doing so by introducing a complexity in another area. The trick is to identify which solution is easier to manage.
No database
The last method is similar to the shared nothing database architecture, except it goes a step further. If the currency-conversion data is already being collected independently by each application instance, why not simply store that data in-memory rather than in a database? This would then eliminate the need for a database altogether (Figure 5).
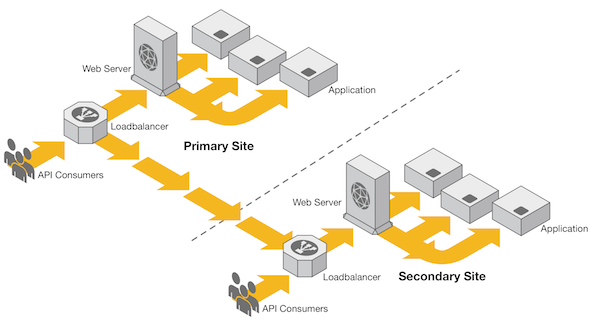 Figure 5
Figure 5
This strategy is popular amongst low-latency applications; these types of applications are often measured by response times. By pulling data straight from memory, a low-latency application can save tens or even hundreds of milliseconds by eliminating network and database calls.
Another benefit to this approach is that it scales horizontally very well. The less dependency an application has on other systems, the more it can scale out to meet scalability demands. Without a database, the API would be able to scale by simply increasing the number of application instances.
While this strategy has the least database complexity, it is often the hardest to implement. It works with our simple currency-conversion API because our currency-conversion data is generated outside of our application. We simply use and distribute it. Even with our simple API example, this approach comes with a few challenges.
For example, whenever an application process restarts with this approach, it must first recollect the currency-conversion data to store in-memory. This can be problematic if the source of data is unavailable after an application restart. With this strategy, it is important to ensure a minimum number of application instances are always available and account for the possibility of data sources being unavailable for an extended period of time.
With no reliance on a database, this strategy is not feasible for every application. Applications that generate unique data and provide that data via an API, for example, would not be able to implement a no database strategy.
Summary
Many times as engineers, we tend to discount strategies that are unique to a single platform. When designing critical systems that require high throughput and availability, it is important to think outside of the traditional IT architecture box.
In the case of the currency-conversion example, we can reduce the complexity of the application by thinking outside of the box and questioning the need for a database altogether. An additional benefit to removing the database is that we are also able to distribute the incoming requests across multiple data centers. So not only do we reduce the complexity of managing our environment, we also reduce the complexity required to manage automated failover or disaster recovery.
However, as with anything, implementing these strategies come with trade-offs. What works for one platform may not fit another. Sometimes, these problems are not even technology problems; rather they are implementation problems.
The goal of our no database design pattern is not necessarily to eliminate all databases. Our goal is to ensure that thought is put into whether a database is really required for the platform.
When databases are not required, avoid using them.
About the Author

Recent Articles
Benjamin Cane
Distinguished Engineer
Cell-Based Architecture for Resilient Payment Systems
How American Express uses cell-based architecture to deliver resilient, low-latency payments at global scale.
Benjamin Cane
Distinguished Engineer

Tristan Fuentes
Principal Engineer
Migrating the Payments Network Twice with Zero Downtime
The architecture and coordination that kept global transactions flowing through complex application and infrastructure changes.