

Published January 14, 2026
Beyond Vanilla RAG: 7 Techniques for Better Retrieval-Augmented Generation
Large Language Models (LLMs) are trained on vast datasets, yet they still struggle when queries require information outside their training data. Correct responses to challenging queries might involve proprietary information, recent events, or specialized knowledge not captured during training. One popular approach to mitigate this issue is Retrieval-Augmented Generation (RAG), which enhances LLMs by leveraging external knowledge to deliver better responses.
The standard, or “vanilla,” RAG process involves the following steps:
- Document Chunking: Splitting a document or article into smaller, manageable chunks.
- Vectorization: Using an embedding model to transform these chunks into vector representations and store them in a vector store along with relevant metadata.
- Similarity Search: When a query is received, the system vectorizes the query using the same embedding model and performs a similarity search to retrieve the top k chunks that are most relevant to the query.
- Response Generation: The query, along with the top k chunks, is passed to an LLM to generate a response based on the retrieved information.
While vanilla RAG is effective in many cases, it is not without limitations. It may fail to retrieve the most relevant chunks or generate accurate responses, especially for more complex or nuanced questions. These limitations have driven significant research efforts aimed at enhancing the basic RAG approach.
In this blog post, we will explore seven advanced RAG approaches grouped by core strategies, including: Reasoning-based, Retrieval reliability, and Knowledge structure-enhanced. Each of these is an improvement from vanilla RAG and each results in better responses from the LLM. By the end of this post, you’ll have a clearer understanding of these advanced techniques and the types of applications they are best suited for.
Reasoning-based: Self-RAG, ActiveRAG, Chain-of-Note, RAFT
Retrieval reliability: CorrectiveRAG, Adaptive-RAG
Knowledge structure-enhanced: Graph-Enhanced RAG
Reasoning-Based
Self-RAG
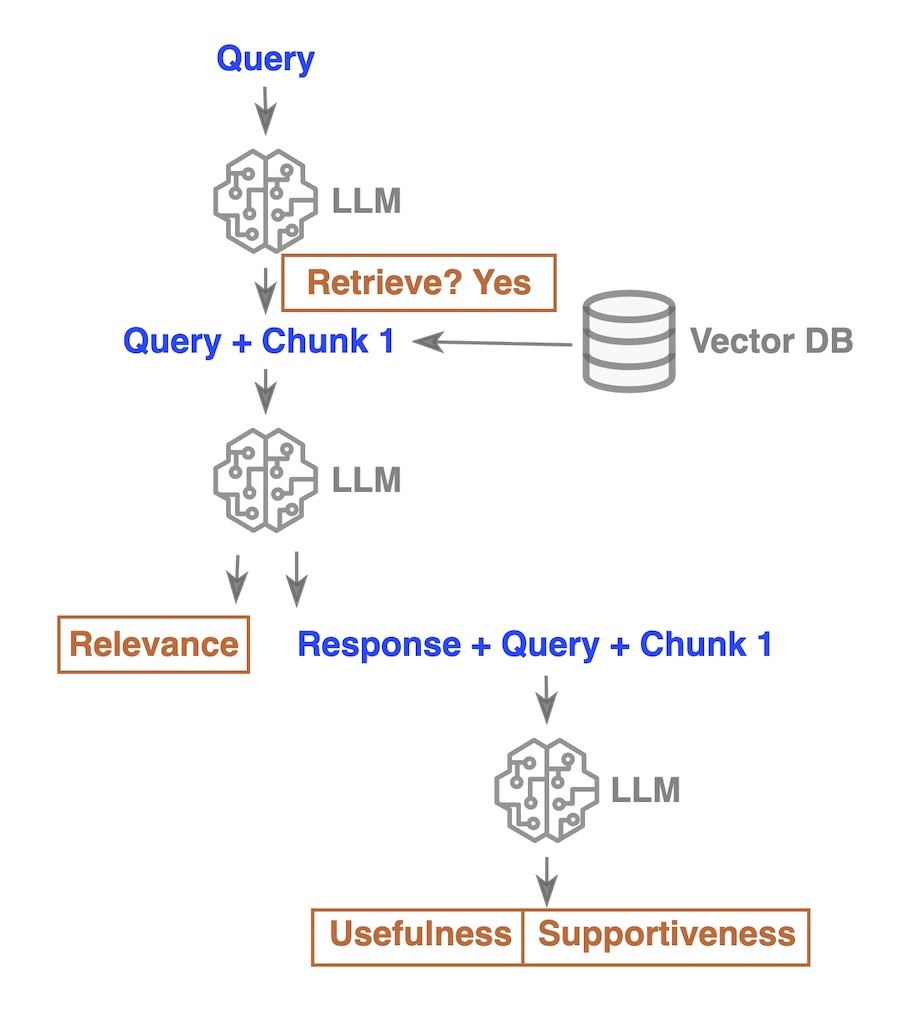
The Self-RAG [1] approach leverages a fine-tuned model to make more informed decisions during the question-answering process. Unlike the vanilla RAG approach, which always retrieves additional context, Self-RAG introduces a conditional retrieval mechanism. Here’s how it works:
-
Initial Query and Conditional Retrieval: The process starts with a query being sent to the model, which then decides whether extra context needs to be retrieved from the vector store. If retrieval is necessary, the model retrieves relevant chunks.
- Chunk Evaluation and Response Generation:
For each retrieved chunk, a two-fold evaluation takes place:
- The model checks if the chunk is relevant to the query.
- Regardless of the chunk’s relevance, the model generates a preliminary response.
- Self-Reflection and Validation:
The generated response, alongside the query and the chunk, is then passed through the model again to evaluate whether:- The response is supported by the chunk.
- The response is useful for answering the question.
-
Re-Ranking Based on “Tokens”:
Self-RAG ranks the retrieved chunks based on three key factors (tokens): Relevance, Usefulness, and Supportiveness (though this ranking step is not depicted in diagram). The top k re-ranked chunks are selected. - Final Answer Generation:
Finally, the top k ranked chunks are sent back to the model one last time, along with the original query, to generate the final, refined answer (not depicted in diagram).
Self-RAG excels at handling single-hop questions, where the answer can be found within a single retrieved chunk. Its success across various benchmarks, such as PopQA, TriviaQA, PubHealth, ARC-Challenge, Biography, and ASQA, is attributed to the multiple rounds of self-reflection and reasoning achieved through repeated LLM calls. This iterative process significantly enhances the model’s reasoning capacity and ensures higher accuracy.
However, there is a trade-off. Self-RAG requires:
- Fine-tuning two large language models.
- Multiple calls to one fine-tuned LLM during the inference stage.
While these factors contribute to its superior performance, they also make Self-RAG less cost-effective, especially for applications requiring real-time responses or operating under strict computational budgets.
ActiveRAG
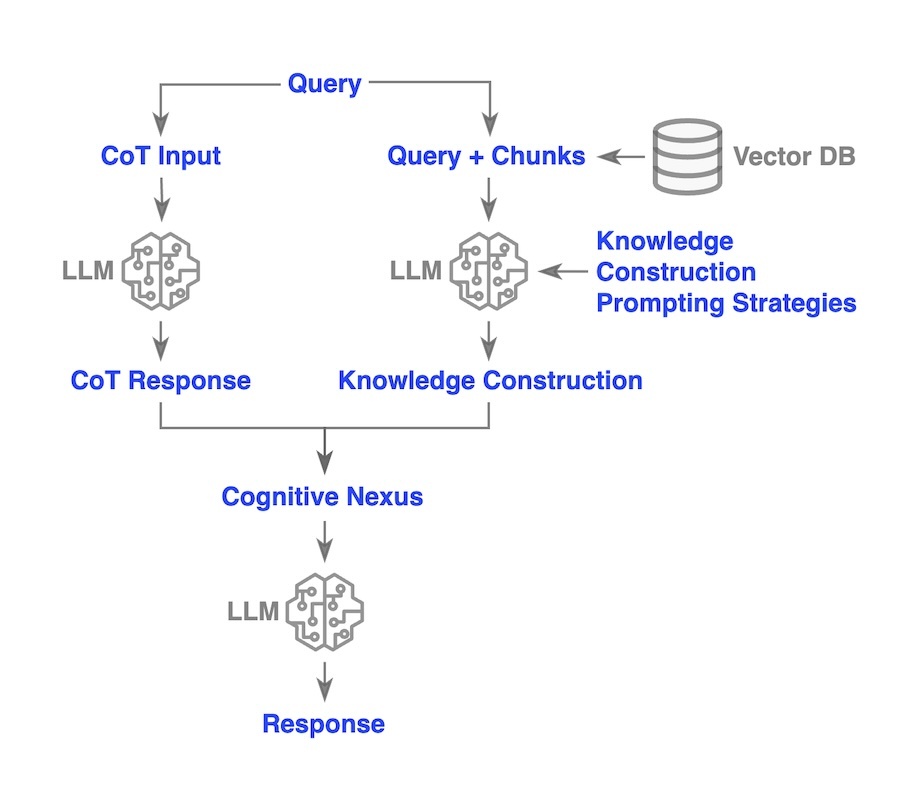
ActiveRAG [2] is a unique approach that can be thought of as dual tasking in parallel. On one hand, a Chain-of-Thought (CoT) query is sent to an LLM to generate a step-by-step reasoning response for the question. Simultaneously, after retrieving relevant chunks based on the query, these chunks are sent to the LLM along with one of four knowledge construction prompting strategies, which enhances the LLM’s reasoning process. For example, one strategy helps the LLM better understand the query and context leveraging the retrieved context.
In the final cognitive nexus step, ActiveRAG integrates the reasoning result from the reasoning process to identify potential errors in the original CoT response, ultimately producing the final, refined answer.
ActiveRAG has outperformed several benchmarks, including Natural Questions (NQ), TriviaQA, PopQA, and WebQ, demonstrating its strength in single-hop questions. This improvement is largely due to the explicit expansion of the LLM’s reasoning capabilities in the knowledge construction step, coupled with the cognitive nexus step, which self-checks the CoT response against the retrieved information.
Unlike some other approaches, ActiveRAG does not require fine-tuning of any large or small LMs. However, it does involve multiple calls to LLMs, which can lead to higher latency and increased computational costs.
Chain-of-Note

The Chain-of-Note [3] approach leverages a fine-tuned model. In this approach, retrieved chunks of information along with the query are passed to the model. The model’s response not only provides the final answer but also includes explanatory notes on how the answer was derived from the retrieved chunks, reducing the risk of hallucination. There are three types of notes that can be generated:
- Relevant (contains the answer): The chunk directly provides the correct answer.
- Irrelevant (model knows the answer): The model already knows the answer independently of the retrieved chunk.
- Irrelevant (model doesn’t know the answer): The chunk does not help, and the model acknowledges uncertainty.
Chain-of-Note has outperformed key benchmarks such as Natural Questions (NQ), TriviaQA, and WebQ, particularly excelling at single-hop questions. This improvement is due to the model’s additional self-refinement steps before producing the final answer, which strengthens its reasoning abilities.
During inference, only a single call to the fine-tuned model is required, which keeps operational efficiency high. However, the data collection process for fine-tuning a model can be resource intensive. For instance, Chain-of-Note leveraged ChatGPT to generate answers with notes for 10,000 questions sampled from the NQ dataset. While the approach is effective, using a more robust, commercial LLM for production deployments may offer better performance. Chain-of-Note could be expensive when developers need to fine-tune a model with their dataset for their use cases.
RAFT
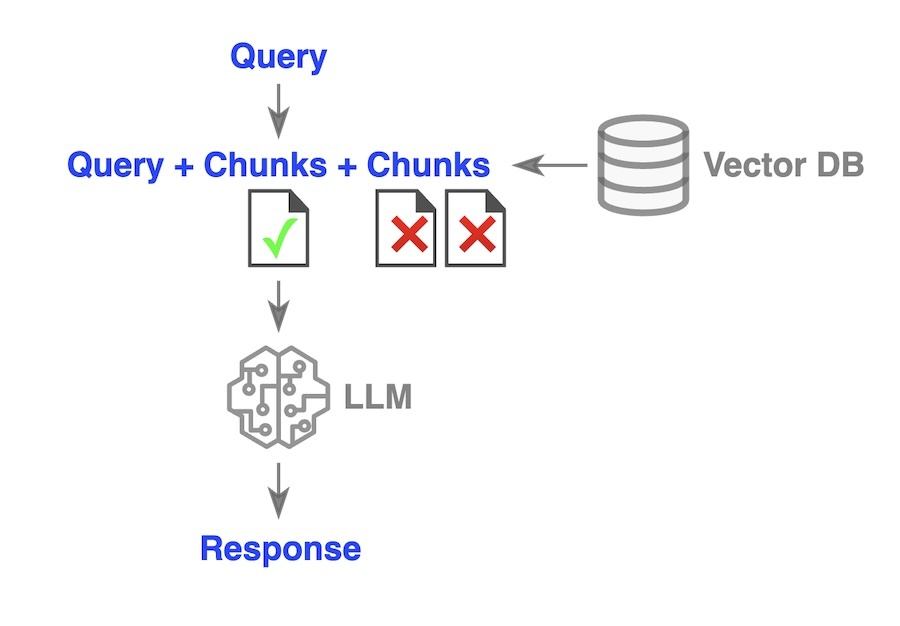
RAFT [4] employs a fine-tuned model. During the training phase, in addition to relevant chunks, RAFT intentionally includes irrelevant chunks in the training datasets. The model generates responses in a Chain-of-Thought (CoT) style, incorporating reasoning and citing relevant documents. This training strategy equips the model to identify and disregard irrelevant chunks during inference, enabling it to provide accurate answers even when such chunks are mistakenly retrieved.
RAFT has surpassed benchmarks such as PubMed, HotPotQA, HuggingFace, Torch Hub, and TensorFlow Hub, showcasing its effectiveness in tackling multi-hop questions. This capability means that generating a correct answer often requires synthesizing information from multiple chunks located in different contexts. RAFT’s exceptional performance on multi-hop questions stems from its enhanced reasoning capacity, allowing it to analyze both relevant and irrelevant chunks concurrently.
At first glance, RAFT may resemble the Chain-of-Note approach; however, its distinctive training methodology sets it apart. By deliberately including irrelevant chunks during training, RAFT bolsters the robustness of its fine-tuned model, ensuring better performance in inference scenarios where irrelevant information may arise. Moreover, it is specifically trained to excel at multi-hop questions rather than just single-hop inquiries.
Retrieval Reliability
CorrectiveRAG
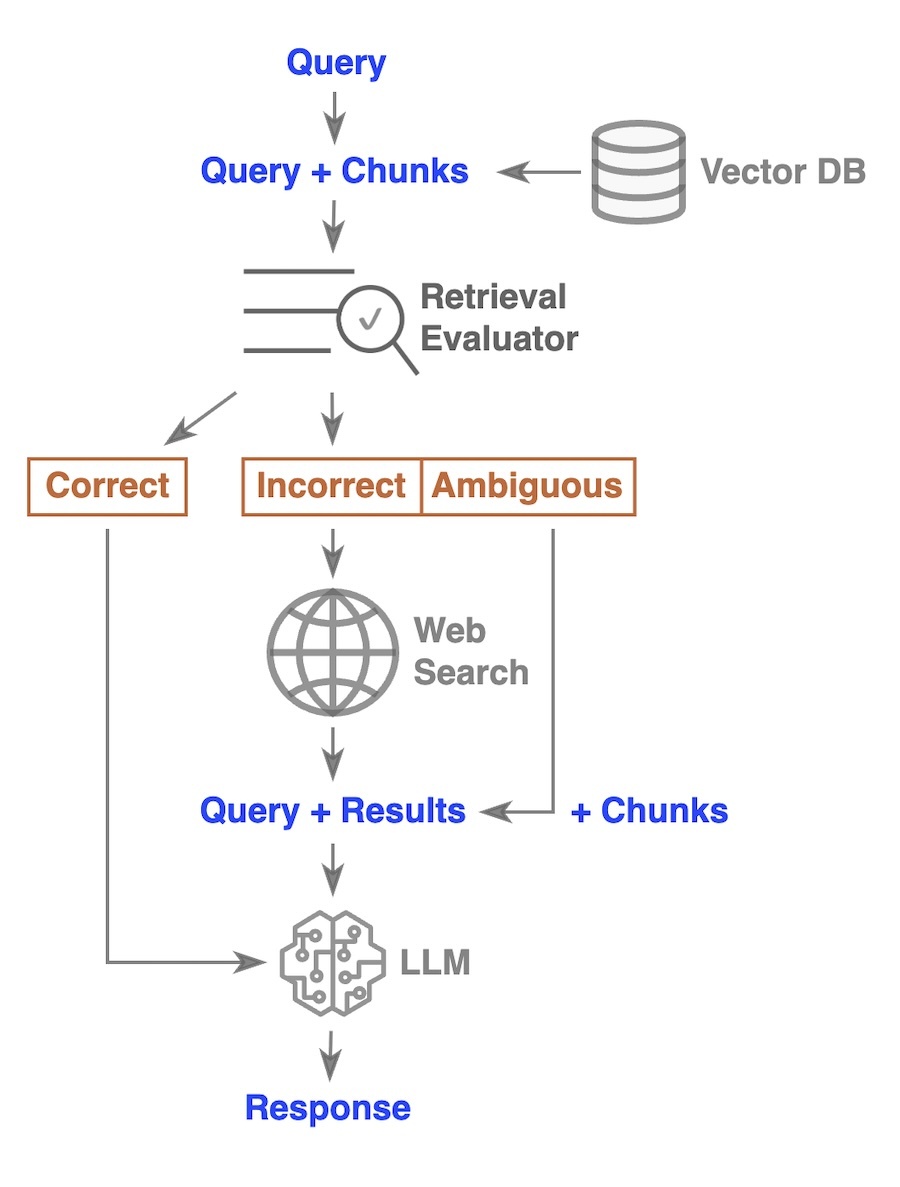
The CorrectiveRAG [4] approach introduces a Retrieval Evaluator, fine-tuned using T5-large, to assess the relevance of retrieved chunks to the query. If the retrieved chunks are accurate, the query and chunks are sent to a large language model (LLM) to generate the final response. However, if the chunks are deemed incorrect, CorrectiveRAG rolls back to a web search, and the query along with the search results are then passed to the LLM for response generation.
In cases where ambiguity arises, CorrectiveRAG combines both the retrieved chunks from the vector store and the search results from the web search, along with the query, and sends them to the LLM for generating a response.
CorrectiveRAG has outperformed benchmarks such as PopQA, Biography, PubHealth, and ARC-Challenge, demonstrating its effectiveness at handling single-hop questions. This performance boost is due to the added evaluation of the correctness of retrieved chunks and the integration of web search results when necessary.
Compared to previous approaches, CorrectiveRAG only requires fine-tuning a small language model (LM) as a classifier. During inference, it requires just one call to a small LM and one call to an LLM, with occasional web searches. This makes CorrectiveRAG more cost-effective than methods that rely on fine-tuning one or more LLMs.
However, the reliance on web searching, when retrieved chunks are ambiguous or incorrect, is a double-edged sword. While web searches can improve the accuracy of answers, certain use cases prohibit external web searching, limiting the applicability of CorrectiveRAG in such environments.
Adaptive-RAG
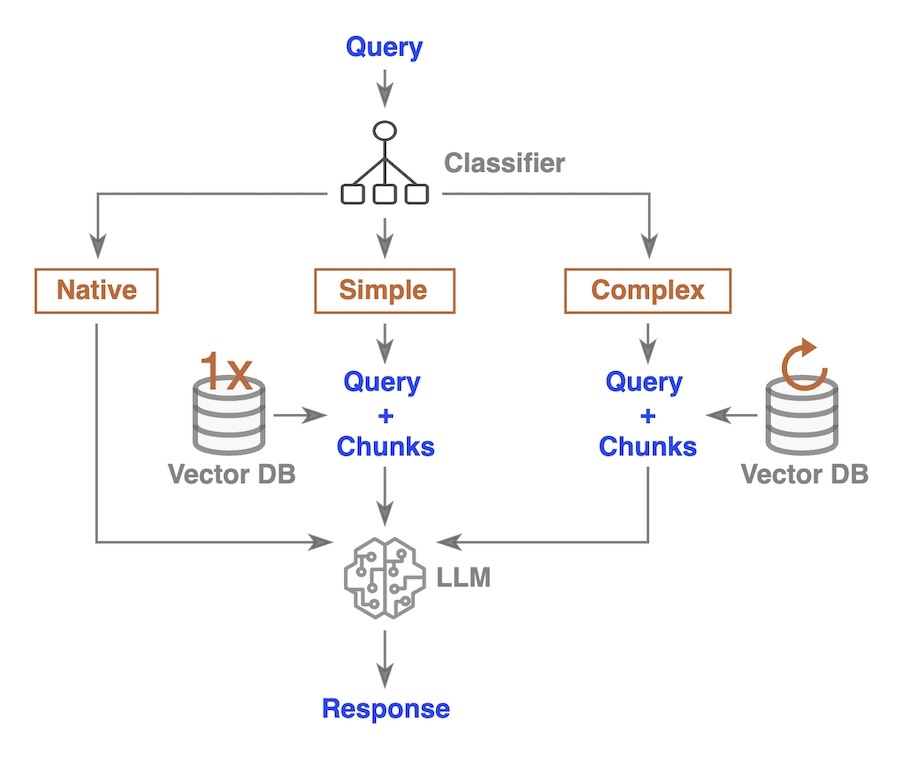
Adaptive-RAG [4] employs a classifier, fine-tuned on T5-large, to assess the complexity of incoming queries. If a query is classified as native, the query is sent directly to an LLM for a response. For simple queries, the system retrieves chunks only once; the query and the retrieved chunks are then sent to the LLM for a response. In the case of complex queries, Adaptive-RAG retrieves chunks multiple times before passing the query and chunks to the LLM for final response generation.
Adaptive-RAG has outperformed benchmarks such as SQuAD, Natural Questions (NQ), TriviaQA, MuSiQue, HotPotQA, and 2WikiMultiHopQA, achieving superior results in either accuracy or cost-effectiveness. This indicates that Adaptive-RAG is efficient at handling both single-hop and multi-hop questions, particularly when incoming queries may vary in complexity.
While both Adaptive-RAG and CorrectiveRAG utilize a small LM as a classifier, they differ in their approaches. Adaptive-RAG classifies the query prior to any chunk retrieval. For native questions, the system sends them directly to the LLM without retrieving additional information. For complex questions, multiple retrievals are performed, but Adaptive-RAG does not revert to web searching. We are curious about the potential outcomes of combining Adaptive-RAG with CorrectiveRAG to leverage their respective strengths.
Knowledge Structure-Enhanced
Graph-Enhanced RAG
Knowledge Graphs can significantly enhance the capabilities of vanilla RAG. To differentiate this general approach from Microsoft’s GraphRAG, which is not the focus of this blog post, we refer to this approach as Graph-Enhanced RAG [7].
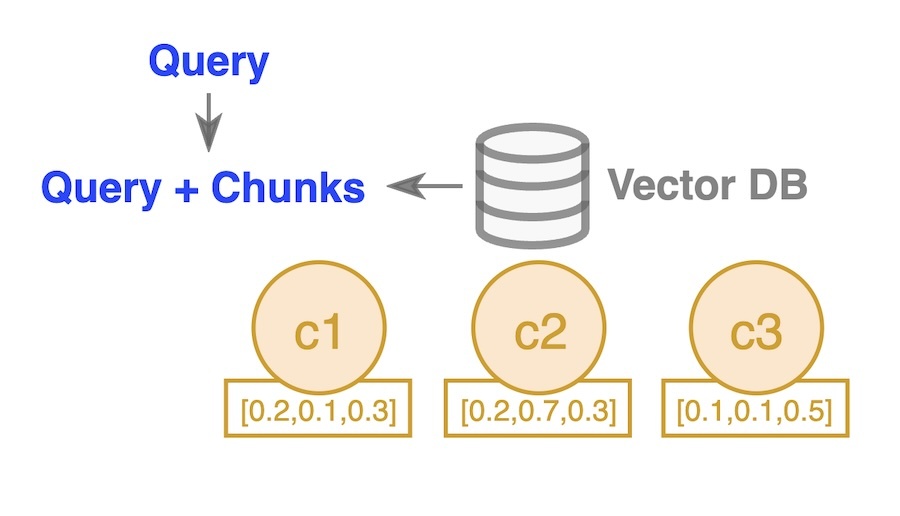
The vanilla RAG approach begins with a vector database that stores the vectors of chunks (e.g., c1, c2, and c3) extracted from articles or documents. The texts of these chunks are stored as metadata linked to their corresponding vectors (this metadata is not depicted in the diagram). When a query is received, the system retrieves the top k chunks from the vector database based on their similarity to the query.
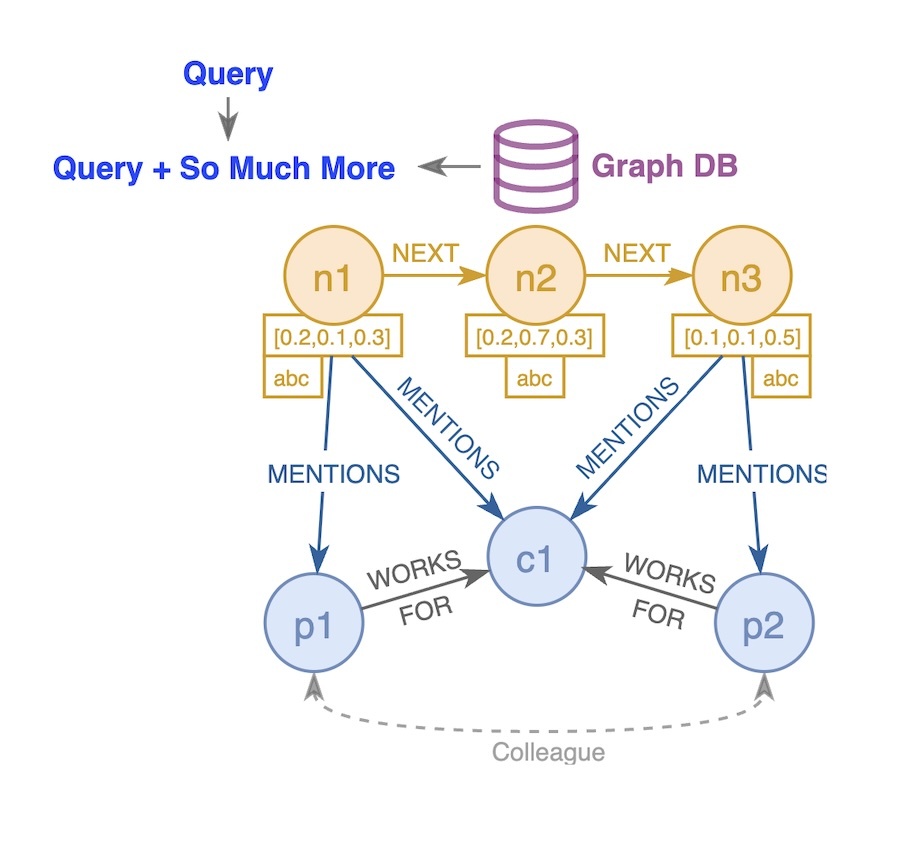
By incorporating a knowledge graph, we can conceptualize the chunks as nodes (e.g., n1, n2, and n3), with the chunk texts and vectors represented as properties of these nodes. Relationships can then be established among the nodes, such as a NEXT relationship that describes the sequence of the chunks.
Subsequently, LLMs can be employed to extract entities from the nodes, including people (e.g., p1 and p2), organizations, companies (e.g., c1), locations, and more. These entities become new nodes within the graph. Relationships between the extracted entities and the original chunks can also be added (e.g., MENTIONS).
Additionally, relationships among the newly created nodes can be identified using LLMs. For example, person p1 works for company c1, and person p2 also works for company c1. We can infer that p1 and p2 are colleagues based on this information.
One of the advantages of Graph-Enhanced RAG is that it does not require fine-tuning any models. When a new context is introduced, developers can easily extend the existing knowledge graph. This approach is particularly effective for multi-hop questions and overarching tasks, where responses may need to synthesize content from across an entire article or document, such as generating a summary.
However, Graph-Enhanced RAG does necessitate calls to LLMs for entity and relationship extraction from the texts of the nodes. Additionally, depending on the size and content of the documents, storing the knowledge graph may require significant space, which can increase costs.
Summary
| # | Name | Need to fine-tune model(s)? | Fine-tuned model size x amount | Applications |
|---|---|---|---|---|
| 1 | Self-RAG | Yes | 7b x 2 | single-hop QA |
| 2 | ActiveRAG | No | n/a | single-hop QA |
| 3 | Chain-of-Note | Yes | 7b x 1 | single-hop QA |
| 4 | RAFT | Yes | 7b x 1 |
single-hop QA multi-hop QA |
| 5 | CorrectiveRAG | Yes | 0.77b x 1 | single-hop QA+ |
| 6 | Adaptive-RAG | Yes | 0.77b x 1 |
single-hop QA multi-hop QA |
| 7 | Graph-Enhanced RAG | No | n/a |
single-hop QA multi-hop QA overarching task |
The table above provides a high-level summary of the seven advanced RAG approaches, highlighting whether each method requires fine-tuning a model, the model size, and the applications for which each approach is best suited.
Overall, there is no single RAG approach that universally fits all use cases. Developers should choose a RAG approach based on their specific question types (e.g., single-hop and multi-hop) and other requirements (e.g., latency is a critical factor and can fine-tune a model.) For instance, if the question set includes a mix of single-hop and multi-hop questions, and latency is a critical factor, developers might consider starting with Adaptive-RAG. Conversely, if the questions are complex and necessitate information drawn from various parts of the context, and fine-tuning a model is not feasible, Graph-Enhanced RAG may be the better option. Advanced RAG approaches will continually evolve with new ones emerging in the future. By leveraging these advanced RAG techniques, we can improve the quality of LLM answers for our use cases.
This article summarizes publicly available research on retrieval-augmented generation (RAG) techniques. It is provided for informational purposes only.
Academic Papers
1. Self-RAG
Asai, A., Wu, Z., Wang, Y., Sil, A., & Hajishirzi, H. (2023). Self-RAG:
Learning to Retrieve, Generate, and Critique through Self-Reflection.
arXiv preprint arXiv:2310.11511.
https://arxiv.org/pdf/2310.11511
2. ActiveRAG
Xu, Z., Liu, Z., Liu, Y., Xiong, C., Yan, Y., Wang, S., Yu, S., Liu, Z.,
& Yu, G. (2024). ActiveRAG: Autonomous Knowledge Assimilation and
Accommodation through Active Retrieval. arXiv preprint
arXiv:2402.13547.
https://ar5iv.labs.arxiv.org/html/2402.13547
3. Chain-of-Note
Yu, W., Zhang, H., Pan, X., Cao, P., Ma, K., Li, J., Wang, H., & Yu, D.
(2023). Chain-of-Note: Enhancing Retrieval-Augmented Generation with
Knowledge Organization. arXiv preprint arXiv:2311.09210.
https://arxiv.org/pdf/2311.09210
4. RAFT
Zhang, T., Patil, S. G., Jain, N., Shen, S., Zaharia, M., Stoica, I., &
Gonzalez, J. E. (2024). RAFT: Adapting Language Model to
Domain-Specific Retrieval-Augmented Generation Tasks. arXiv preprint
arXiv:2403.10131.
https://arxiv.org/pdf/2403.10131
5. CorrectiveRAG
Yan, S.-Q., Gu, J.-C., Zhu, Y., & Ling, Z.-H. (2024). Corrective
Retrieval-Augmented Generation. arXiv preprint arXiv:2401.15884.
https://arxiv.org/pdf/2401.15884
6. Adaptive-RAG
Jeong, S., Baek, J., Cho, S., Hwang, S. J., & Park, J. C. (2024).
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language
Models through Question Complexity. arXiv preprint arXiv:2403.14403.
https://arxiv.org/pdf/2403.14403
Graph-Enhanced RAG and Related Resources
7. Neo4j Product Examples – SEC EDGAR Data Prep Repository
Neo4j Product Examples. (n.d.). Data Preparation for SEC EDGAR
Knowledge Graph Examples. GitHub repository. Retrieved November 2025,
from https://github.com/neo4j-product-examples/data-prep-sec-edgar
8. DeepLearning.AI Short Course
DeepLearning.AI. (n.d.). Knowledge Graphs & Retrieval-Augmented
Generation [Online short course]. Retrieved November 2025, from
https://www.deeplearning.ai/short-courses/knowledge-graphs-rag/
About the Author
