

Published June 11, 2026
Cell-Based Architecture for Resilient Payment Systems
Architecture Payments Resiliency
The American Express core payments ecosystem is a global platform relied on by Card Members and partners around the world. Every day, it processes live payment transactions that require high availability, low latency, and predictable performance.
Resiliency is not an afterthought; it has been encoded into the system’s design from the beginning. Localized faults are contained within defined boundaries, and recovery is designed to be fast and predictable.
To achieve this, the platform is built around a cell-based architecture that isolates failures, maintains low-latency processing, and scales capacity without expanding the failure domain.
This blog outlines the principles that guide this architecture and how they help us build a resilient payments latform at global scale.
Core Payments Ecosystem
In 2018, we started a journey to modernize our core payments ecosystem. This platform processes live card and payment transactions and is mission-critical to our Card Members and partners.
As we modernized the platform, resiliency remained a primary design requirement. We needed an architecture that could continue processing transactions reliably, even when individual components failed. This decision was heavily influenced by our historical design patterns, which predated the term “cell-based architecture,” but share many of the same principles.
Our new platform targeted cloud-native technologies, which meant we needed to think differently about how we designed for resiliency and scalability.
In the next sections, we’ll discuss some of the design principles we follow in our core payments ecosystem and how they not only improve our ability to process payments reliably but also help us reduce latency and scale more easily.
What is Cell-based Architecture?
Cell-based architecture is an architecture pattern that has gained popularity in the cloud-native distributed systems space.
The idea behind the concept is to group related microservices, databases, and other components into independent instances called cells. Each cell is able to function independently without reliance on other cells.
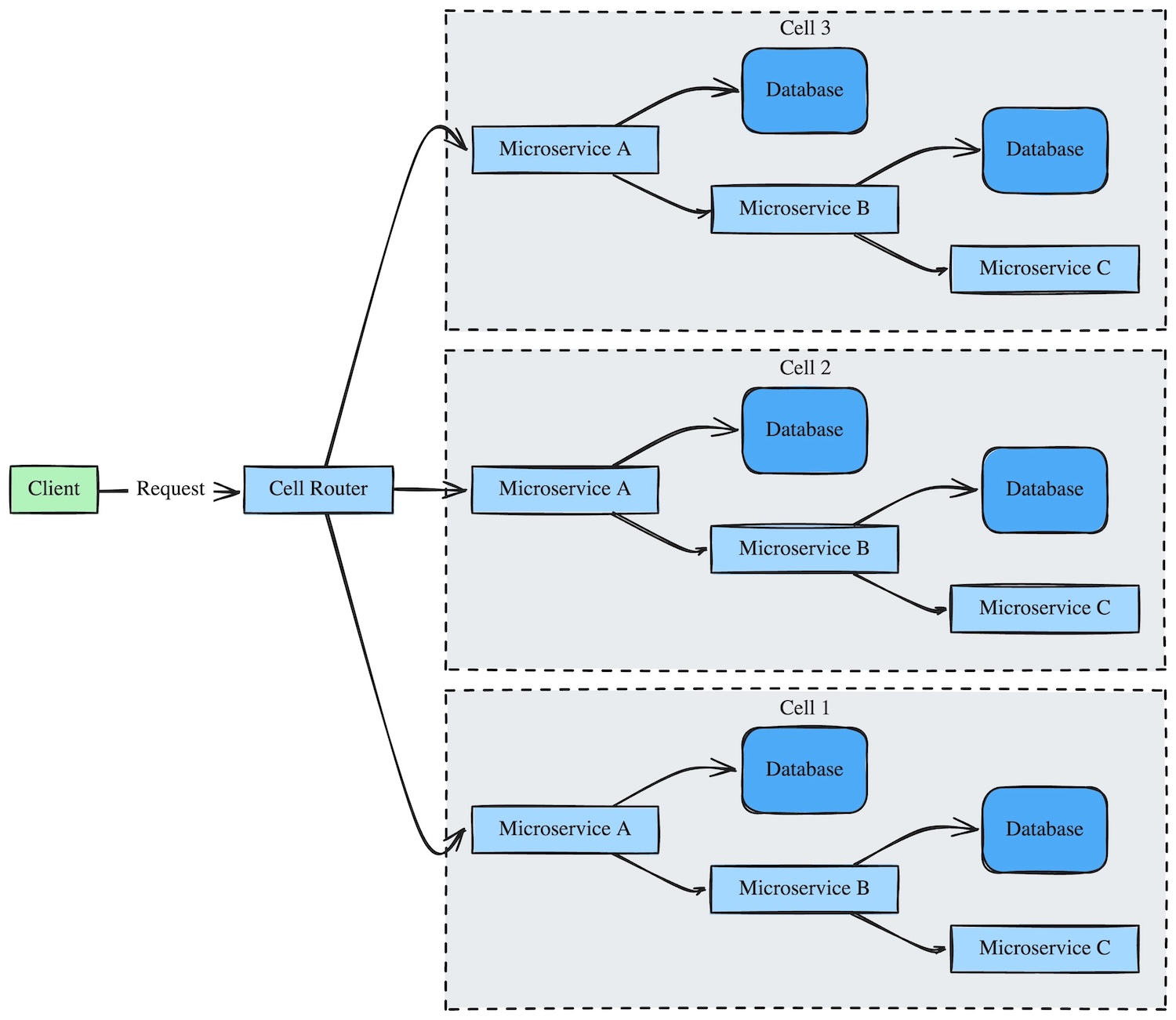
In this diagram: Each cell contains its own services and data so a failure stays within that cell instead of spreading across the platform.
The primary benefit of cell-based architecture is reducing the blast radius of failures. With each cell being independent, if one cell experiences issues, it doesn’t impact the others. The trade-off is that cell-based architecture often increases management overhead and architectural complexity, as it requires careful design to ensure that cells are truly independent and that data is appropriately localized.
However, for mission-critical systems like payments, we find that the benefits of a reduced blast radius and improved resiliency outweigh the additional complexity.
We’ve also found that when implemented well, a cell-based architecture can help platforms reduce latency (by reducing external dependencies and network hops) and improve scaling by introducing additional independent cells.
How We Follow Cell-Based Architecture
Each instance of our core payments ecosystem is designed as a cell, which:
- Is an independently deployable unit that can process payments on its own.
- Has its own set of microservices, databases, and other components.
- Is a single failure domain, meaning that if one cell experiences issues, it doesn’t cascade the failure beyond the cell boundary.
- Can be taken out of rotation for maintenance or in response to failures without impacting the overall system or requiring coordination with other cells.
- Has no synchronous cross-cell dependencies in the critical path of processing transactions.
A cell is defined by its failure boundaries rather than a specific infrastructure construct. In practice, cells never span multiple regions—everything required to process transactions (DNS, databases, microservices, and supporting services) remains local within that boundary.
To achieve this, we follow a set of core principles that guide our design decisions and help us ensure that our cells are truly independent and resilient.
Data and Processing Locality by Default
Processing payments requires data: currency rates, merchant category codes, and so on. Some data is static, while some data changes with each transaction.
Static & Semi-Static Data Replication
For static or semi-static data like currency rates and merchant category codes, we replicate that data to each cell.
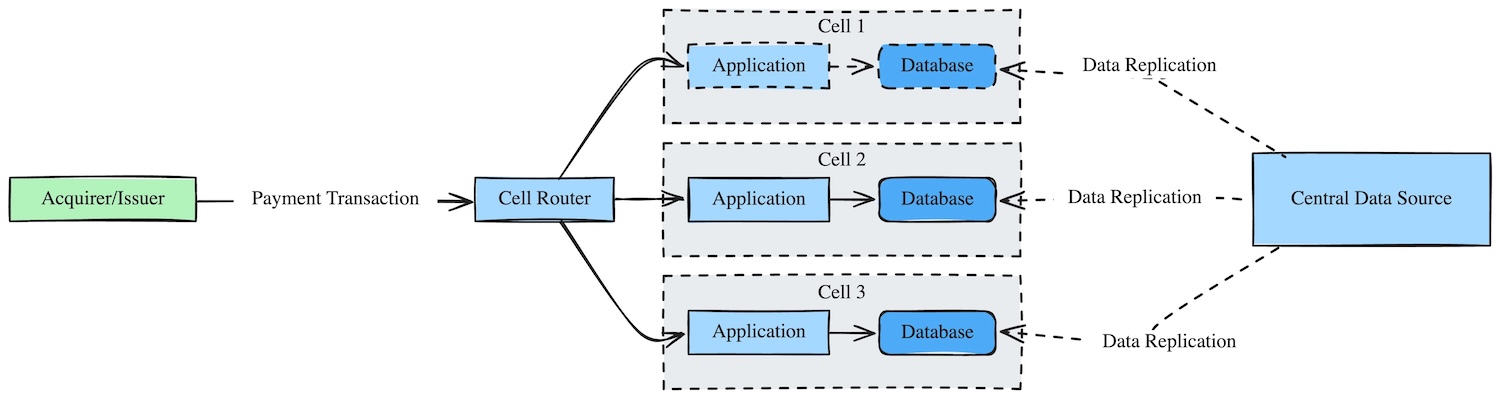
In this diagram: Reference data is pushed into every cell ahead of time so transaction processing never needs a synchronous lookup to a central source.
Rather than relying on a fall-through read to a centralized system of record during transaction processing, we pre-populate this data in each cell ahead of time. This keeps reference data local before transactions arrive, avoids cache-miss latency during processing, and preserves critical-path isolation.
The replication work happens outside the transaction path, which lets us keep the data available locally without introducing synchronous cross-cell dependencies.
Dynamic Data Routing
Not all data is static and not all data can be pre-populated. For more dynamic data (data that changes with each transaction), data replication may not be fast enough to ensure that every cell has the right data at the right time. We don’t want to route transactions to cells that don’t have the latest data, as that would increase latency and potentially lead to processing failures.
Instead, we use deterministic routing to route transactions to the cell where the right data is already available. In a recent article, Migrating the Payment Network Twice with Zero Downtime, we introduced the Global Transaction Router, which is responsible for managing connectivity and routing transactions to the appropriate cell. It can do so because it understands just enough of the payment specifications to make routing decisions based on the transaction data.
For example, we may route transactions based on partner, market, or payment type; how we route depends on the payment transaction data and the use case, but the key is that we selectively route transactions to where they are needed when there is a need for strong data consistency across transactions.

In this diagram: The router sends a transaction to the cell that already has the authoritative dynamic state, while replication continues asynchronously outside the critical path.
We keep transaction processing localized by restricting microservice communication to pod-to-pod interactions within the cell’s Kubernetes network, ensuring all processing remains within the cell’s boundaries.
To ensure failover data is synchronized across cells using message-based replication, that replication happens asynchronously outside the transaction path, so it doesn’t impact latency or availability.
No in-flight transaction waits for replication to complete; if the latest state is required, the Global Transaction Router sends the transaction to the cell where that data is already authoritative or available.
We only allow our microservices to talk to localized database instances. This keeps latency predictable and avoids unnecessary network hops, but it requires deliberate routing decisions.
By introducing deterministic routing at the edge, we can ensure that transactions are routed to the cell where the right data is already available.
Enforced Boundaries for Ingress and Egress
Along with its routing capabilities, the Global Transaction Router also serves as a key enforcer of our “local only” processing.
Transactions must enter a cell through the Global Transaction Router; if a cell cannot process a transaction and that transaction needs to be rerouted to another cell, it must also go through the Global Transaction Router.
In this way, the Global Transaction Router also serves as a payments mesh, connecting our cells globally.
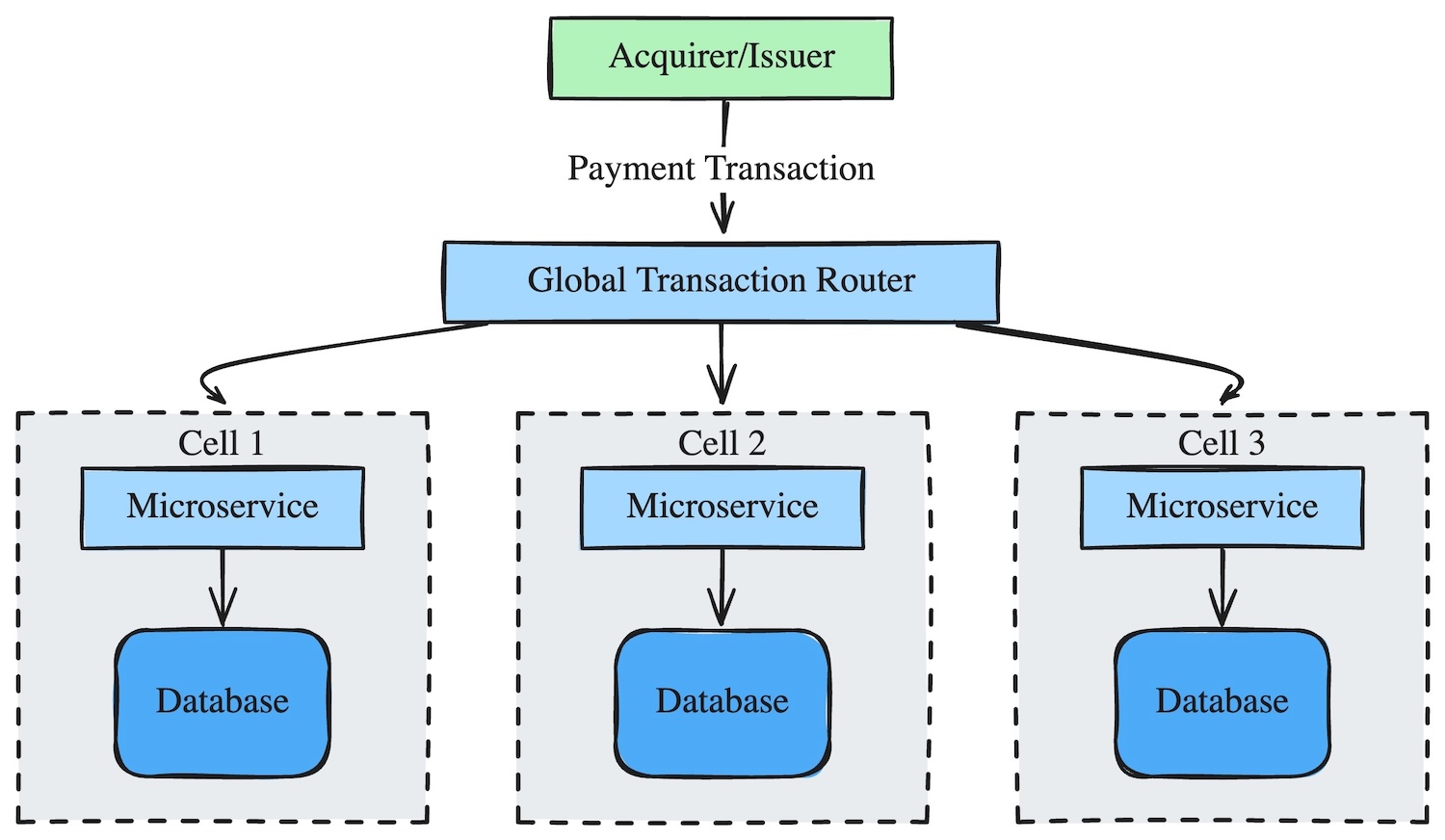
In this diagram: All cross-cell traffic is funneled through the Global Transaction Router, which preserves strict cell boundaries.
Preventing cross-cell dependencies becomes increasingly difficult as platforms grow.
By tightly controlling cross-cell communication through the Global Transaction Router, we prevent cells from forming strong dependencies on each other, as they do not have the ability to communicate at all—only the Global Transaction Router can communicate across cells.
This enforcement occasionally results in duplicated services where shared implementations might otherwise seem simpler, but it preserves cell independence and improves latency by reducing cross-cell network hops.
The same principle applies to observability. Each cell publishes logs, metrics, and traces to observability components localized within that cell first, so losing part of the observability stack only reduces visibility for that cell instead of the entire platform. We still aggregate observability data asynchronously to provide global dashboards, alerting, and fleet-wide analysis, but that aggregation remains outside the transaction’s critical path.
Cells Break in Isolation; Other Cells Replace Them
Leveraging the ability to reroute transactions to other cells is a key part of our resiliency strategy.
When failures occur, their impact stays contained within the affected cell, and transactions are automatically rerouted to a healthy cell where processing restarts.
We reroute not only new incoming transactions but also transactions that were already in-flight in the failing cell.
Our Payments Processing subsystem follows an orchestrated microservices architecture, where an orchestrator microservice manages the processing workflow and calls other microservices to perform specific tasks.
If a downstream service begins to fail, the orchestrator detects the failure, halts processing, and sends the transaction back to the Global Transaction Router to be rerouted to another cell.
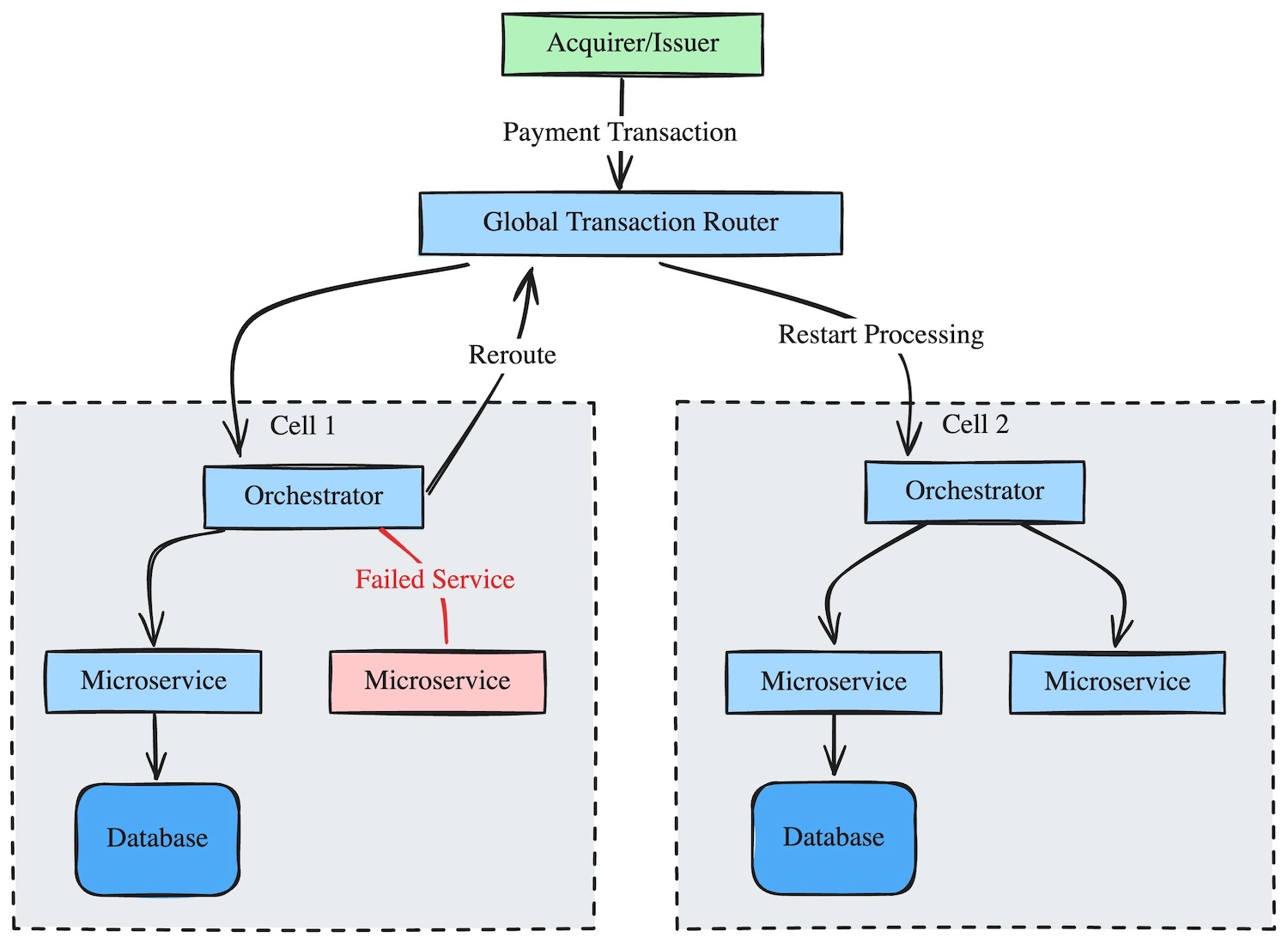
In this diagram: When a cell fails mid-flow, the transaction is rerouted and restarted in a healthy cell rather than resumed across cells.
We do not attempt to resume partially processed transactions across cells. Instead, we restart transaction processing in another cell with the original transaction data.
This restart is only safe while the transaction is still within the core payments ecosystem. Once a transaction has been sent to an external system (e.g., card issuer), we consider that a point of no return, and we don’t allow transactions to be rerouted after that point.
Card authorizations are structured so that the point of no return is toward the end of processing. If a transaction fails before the point of no return, we can safely reroute and restart processing without worrying about duplicate transactions or data consistency issues.
For other payment types, we manage idempotency through transaction identifiers. Each transaction carries a unique transaction identifier that remains consistent across retries and reroutes. Downstream systems use these identifiers to detect and suppress duplicate requests, allowing retries and reroutes to be handled safely without introducing inconsistencies or duplicate transactions.
The restart model emphasizes the importance of avoiding shared state between cells. Cross-cell shared state would introduce synchronization challenges and potential consistency issues, especially during failover scenarios. Communication failures between cells could impact the ability to process transactions globally, which we want to avoid at all costs for a payments system.
In our architecture, cells are designed to be loosely coupled. Each cell has its own database clusters, and the microservices within a cell only communicate with the local database cluster.
When a cell fails, its impact stays confined to that cell, allowing other cells to continue processing transactions normally.
When rerouted, transactions are processed without reliance on state from the previous cell.
At any point in time, a cell can be taken out of rotation. When a cell is taken out of rotation either automatically or manually, another cell takes its place. This does not have to be a binary cutover. As discussed in Migrating the Payment Network Twice with Zero Downtime, the Global Transaction Router can shift traffic between cells by percentage, allowing us to gradually drain a cell for maintenance, validate a recovering cell under partial load, or respond more safely during incidents.
Minimal Dependencies at the Edge
With the Global Transaction Router at the edge, it’s a critical service providing connectivity, routing, and resiliency. To ensure its availability, we aim to keep dependencies within this system as small as possible.
The closer to the edge, the fewer dependencies we aim for.
But we don’t just reduce the dependencies; we also aim to keep them out of the critical path.
If our logging infrastructure becomes unavailable, we don’t want that to impact the ability to process transactions. We do this by using an asynchronous logger configured with a buffer truncation policy, so if the buffer is full, we drop logs instead of blocking transaction processing.
If our configuration service becomes unavailable, we want to continue running with the last known configuration. For this, we maintain an in-memory configuration that is updated asynchronously, so if the configuration service becomes unavailable, we can continue running with the last known configuration until it becomes available again and we can pull the latest configuration.
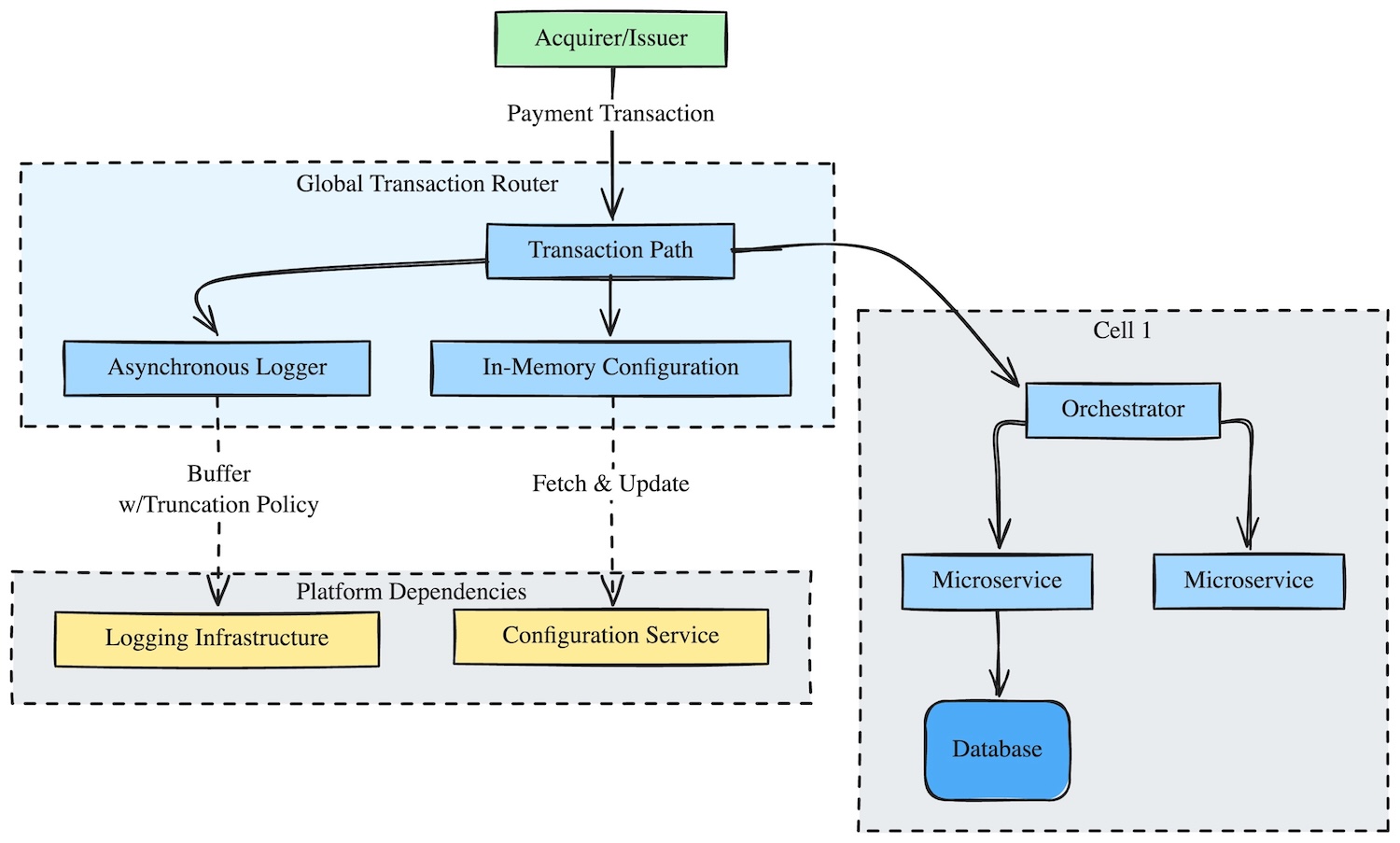
In this diagram: The edge path stays thin and resilient by handling logging and configuration asynchronously instead of letting those dependencies block transactions.
Keeping dependencies out of the critical path reduces failure points. This requires deliberate trade-offs: accepting degraded non-critical functionality (logging, metrics) to preserve transaction processing.
Summary
In distributed payments systems, resiliency isn’t achieved through monitoring and retries alone—it’s achieved by defining clear failure boundaries and enforcing them through design.
By organizing our core payments ecosystem into isolated, independently recoverable cells, we transform major failures into controlled routing decisions. Locality, deterministic routing, idempotent processing, and strict boundary enforcement work together to ensure growth and change don’t increase risk.
This discipline underpins our cell-based architecture, enabling us to operate a global payments platform with low latency and high resiliency—principles that continue shaping our evolution.
About the Author

Recent Articles
Benjamin Cane
Distinguished Engineer

Tristan Fuentes
Principal Engineer
Migrating the Payments Network Twice with Zero Downtime
The architecture and coordination that kept global transactions flowing through complex application and infrastructure changes.
Benjamin Cane
Distinguished Engineer
Go at American Express Today: Seven Key Learnings
A look into pain points of adopting Go at American Express and how we and the language have evolved.