

Published March 02, 2026
When Human Feedback Is Scarce, How Do You Evaluate AI?
Evaluating AI systems is easy… until it isn’t.
For many user-facing applications like travel planning, clinical note drafting, or conversational agents, there is no single “right answer.” The most reliable signal of quality is human feedback: ratings, preferences, or real-world behavior. That’s because quality is subjective, contextual, and often best judged by people. As a result, human feedback such as ratings, preferences, and real-world behavior is the most reliable signal we have.
But in early-stage systems and research prototypes, that signal is often too sparse, too expensive, or too slow to guide development. This creates a gap between how AI systems are evaluated in research settings and how they need to be evaluated in real-world deployment.
This challenge sits at the heart of a new ICLR paper, AutoMetrics: Approximate Human Judgments with Automatically Generated Evaluators, authored by researchers from American Express and Stanford HAI.
The work introduces a practical open-source framework for transforming small amounts of human feedback into scalable and interpretable evaluation metrics, helping teams move from prototypes to production with greater confidence.
From Expensive Human Labels to Practical Metrics
Today, when evaluating AI systems, there is often a trade-off between two imperfect options:
-
Human evaluation: Accurate but costly and slow.
-
LLM-as-a-Judge: Fast and inexpensive but can be brittle and often poorly aligned with what users actually care about.
AutoMetrics offers a third path.
The key idea is simple but powerful: instead of relying on a single evaluator, AutoMetrics learns a weighted combination of evaluation metrics that best matches human judgment, using fewer than 100 feedback points.
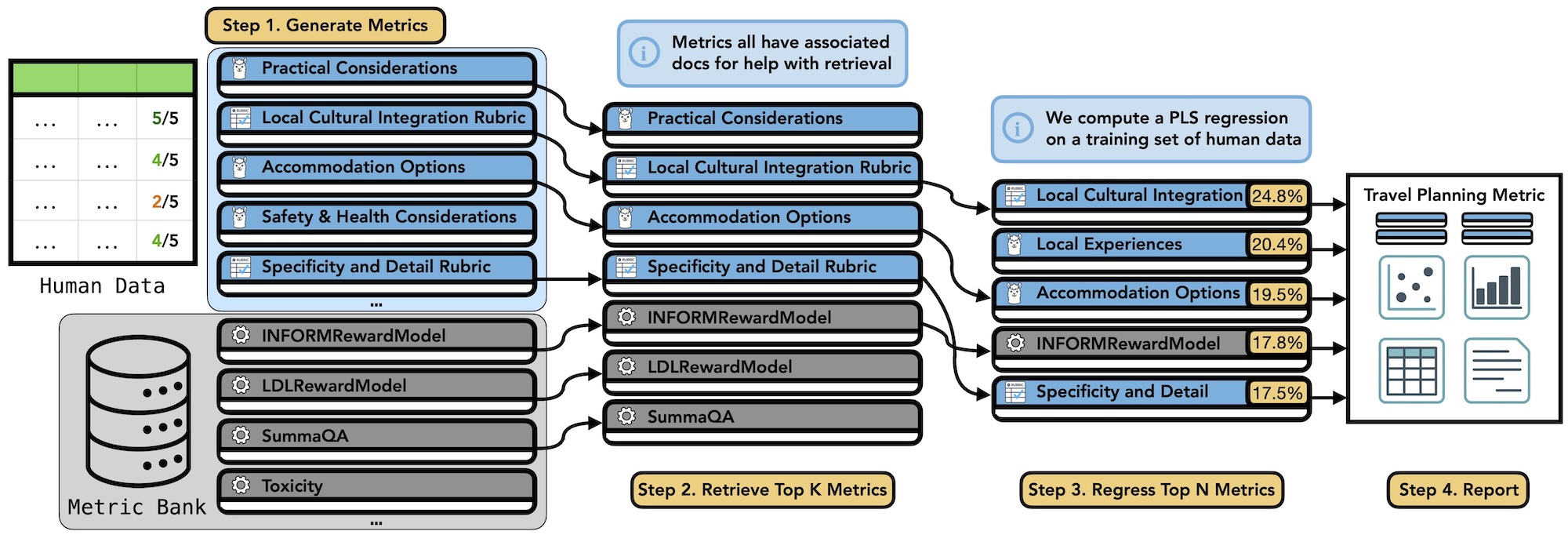
The framework operates in four steps:
-
Generate candidate metrics
AutoMetrics automatically creates task-specific evaluation criteria (e.g., clarity, usefulness, policy compliance) using LLMs.
-
Retrieve existing metrics from MetricBank
The system draws from MetricBank, a curated library of 48 well-documented evaluation metrics spanning tasks like summarization, dialogue, code generation, and safety.
-
Learn how to combine them
Using lightweight regression, AutoMetrics identifies which metrics matter most and how they should be weighted to best predict human feedback.
-
Report interpretable evaluators
The output isn’t just a score—it’s a breakdown of why a system is performing well or poorly.
The result is an evaluation signal that is data-efficient, adaptive, and explainable.
Stronger Alignment with Human Judgment
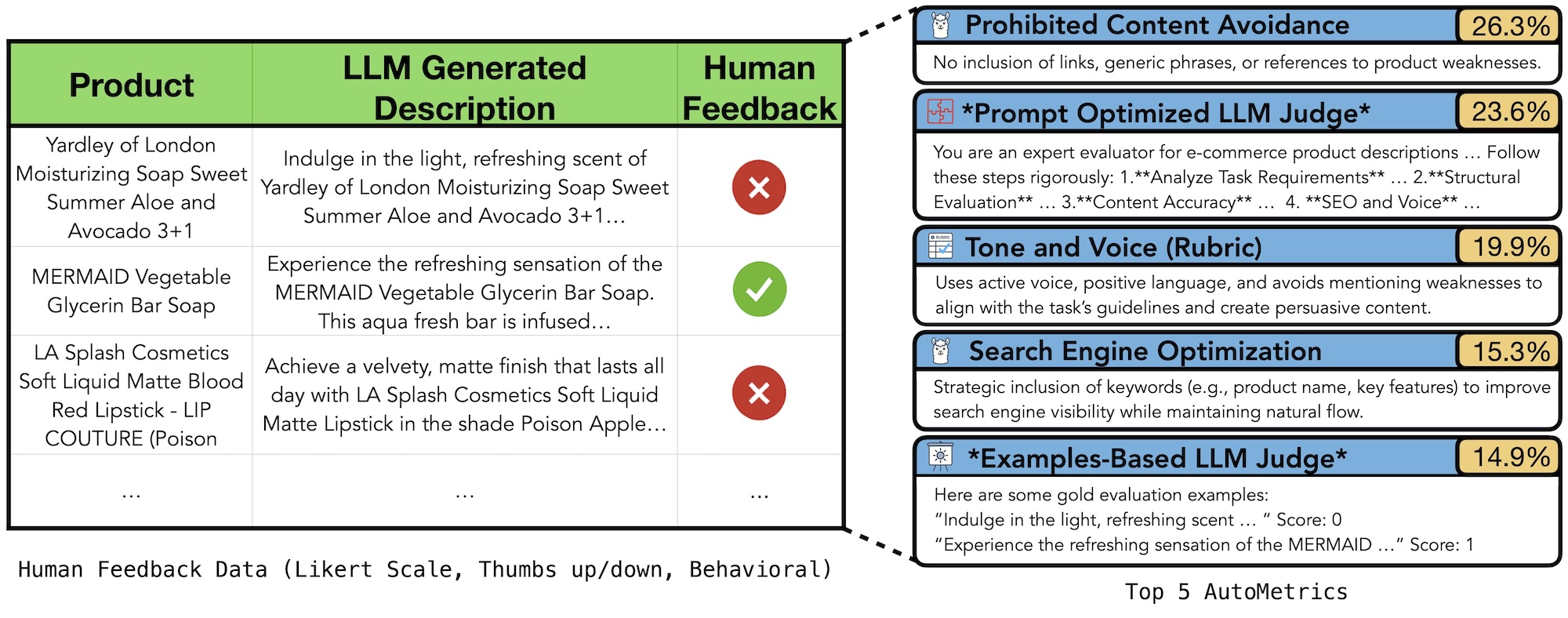
The paper analyzes AutoMetrics across five diverse tasks, including dialogue, product description generation, code completion, and travel planning. Across these settings, AutoMetrics consistently outperforms strong baselines.
It improves correlation with human ratings by up to 33.4% compared to standard LLM-as-a-Judge approaches.
-
Performance saturates with approximately 80 human feedback examples, making it practical even for low-data settings.
-
The learned metrics remain stable under irrelevant changes and sensitive to real quality degradations, a key requirement for trustworthy evaluation.
In other words, AutoMetrics doesn’t assign scores, it behaves like a reliable proxy for how people actually judge quality.
Evaluation That Can Drive Optimization
One of the most compelling findings goes beyond measurement. The authors show that AutoMetrics can be used as a proxy reward signal to optimize an AI agent, matching or even exceeding the performance of systems trained with a fully verifiable reward. In a realistic airline-assistance benchmark, agents optimized with AutoMetrics improved at the same rate as those trained with explicit ground-truth rewards.
This opens the door to human-aligned optimization in domains where rewards are subjective, ambiguous, or hard to formalize.
Why This Matters
For practitioners building real-world AI systems, AutoMetrics points to a future where:
-
Evaluation adapts as products evolve
-
Small amounts of user feedback go much further
-
Metrics are understandable enough to guide iteration, not just leaderboard scores
By releasing AutoMetrics and MetricBank as open-source tools, the authors aim to make adaptive, human-aligned evaluation a standard part of the AI development workflow.
Looking Ahead: Evaluation That Keeps Pace with AI
As AI systems move faster from prototype to production, evaluation can no longer be an afterthought or a bottleneck. AutoMetrics shows that it’s possible to ground evaluation in human judgment without requiring massive labeling efforts, and to do so in a way that remains explainable adaptive, and actionable.
The broader implication is clear: evaluation itself must become a learning system. By discovering what users actually value and translating that signal into scalable metrics, AutoMetrics reframes evaluation as a first-class component of AI development, rather than a scorecard at the end. These metrics can then be used to optimize AI Agent configurations.
For teams building AI in open-ended, user-facing domains, this work points toward a future where small amounts of real feedback can drive rapid iteration, reliable optimization, and more human-aligned systems from day one.
As the community continues to explore adaptive evaluation, AutoMetrics provides both a practical toolkit and a compelling blueprint for how we measure progress in AI—when the only true reference is human judgment.
Read the full ICLR paper:
AutoMetrics: Approximate Human Judgments with Automatically Generated
Evaluators
Note: This research is part of an industrial affiliate program.
About the Author

About the Author
